C’est quoi un serveur http ? – Partie 2
C’est quoi un serveur web ?
![]() <<< Suite de l’article C’est quoi un serveur http ?
<<< Suite de l’article C’est quoi un serveur http ?

Dans l’article précédent, nous avons vu globalement comment fonctionnait le protocole http.
Je vous propose maintenant d’entrer un peu dans le détail.
J’ai classé cet article en niveau bleu (intermédiaire) car il est peu plus technique que le précédent.
Entrons un peu dans le détail du protocole http.
Préambule
Ce protocole comme beaucoup de protocoles de l’Internet fonctionne en mode texte. Les commandes échangées entre le client et le serveur http sont envoyées en texte non crypté. (dans l’article sur la différence entre le http et le https, nous verrons qu’il est parfois nécessaire de crypter certaines informations).
Et enfin, un client de serveur http est le plus souvent un navigateur Internet. Actuellement, pour lire cette page, vous utilisez un navigateur tel que : Internet Explorer, Opera, Chrome, Firefox, … n’est-ce pas ?
Réception du contenu
La plupart du temps, le contenu demandé est une page, affichée ensuite par le navigateur. Mais nous l’avons vu dans l’article précédent, il est possible de demander différents contenus aux serveurs.
Voici comment cela se passe : (c’est le même schéma que sur la 1ère page de cette série d’article, mais nous allons examiner cela en détail)
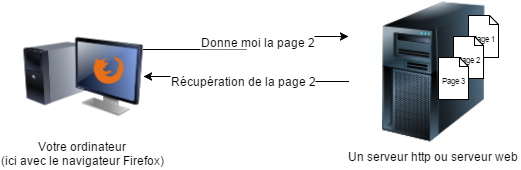
Attention : ce schéma est volontairement simplifié, il manque la partie connexion et déconnexion au serveur. Vous retrouverez le schéma complet plus bas. Nous allons rester volontairement sur ce schéma pour l’instant car il facilite la compréhension et nous permet de nous concentrer sur le protocole http (ou https).
Comme dans toute communication, il faut parler le même langage. Le protocole (langage) pour dialoguer avec le serveur web est « http ».
La méthode GET.
Et comme dans tous langages, les actions/commandes se font à partir de verbes. Le navigateur va demander le contenu au serveur à l’aide de la commande : « GET » ( Le verbe « to Get » en anglais se traduit par « obtenir », « avoir », « se procurer » : On pourrait donc traduire « GET » par « Obtiens » ou « Récupère » ).
Ces commandes sont appelées des « Méthodes« .
La méthode Get va envoyer différentes informations au serveur pour que celui-ci puisse lui renvoyer le contenu demandé.
Voici les informations que la méthode Get envoie au serveur :
- Evidemment : la page demandée (ou le contenu demandé)
- le numéro de version du protocole http utilisé,
- le langage utilisé,
- le navigateur utilisé,
- les cookies, (c’est quoi les cookies ?)
- la conservation de la connexion,
- …
Et comme je vous le disais au dessus, toutes ces informations sont envoyées en texte. Chaque information est envoyée sur une ligne séparée.
Un exemple pour comprendre
Regardons les étapes lorsque je me connecte au site « www.culture-informatique.net » et que je demande la page « C’est quoi une adresse IP ? »
J’ai mis la partie connexion/déconnexion au serveur en italique car nous en reparlerons plus bas : restons concentré sur la partie http.
- Le navigateur se connecte au serveur.
- Le navigateur envoie la méthode GET au serveur (en passant éventuellement des paramètres que examinerons plus loin)
- Le serveur trouve la page demandée et la renvoie vers le navigateur.
- La navigateur affiche la page récupérée.
- Fermeture éventuelle de la connexion.
Et dans le détail, voila ce que ça donne :
- Le navigateur se connecte à https://culture-informatique.net
- Le navigateur envoie la méthode : GET /c-est-quoi-une-adresse-ip-niv1 (la méthode GET suivi de la page à récupérer, ici : /c-est-quoi-une-adresse-ip-niv1)
- Le serveur envoie la réponse et le navigateur récupère les données et affiche la page.
- Fermeture (ou pas) de la connexion.
Et voila, c’est aussi simple que ça.
Pour vous le prouver, voici les données envoyés par le navigateur Internet (Il s’agit de données extraites à l’aide du logiciel Wireshark qui permet de voir toutes les données qui circulent sur le réseau).
Pour conserver la simplicité de cet article, j’ai mis les informations récupérées par Wireshark sur une autre page, cliquez ici pour voir cette page. (ce n’est pas obligatoire pour la compréhension du reste).
L’envoi de données.
Nous venons de voir le principe de fonctionnement pour des pages qui ne changent pas comme des articles, mais que se passe-t-il quand l’utilisateur doit envoyer des données et quand les pages doivent changer en fonction des données envoyées ?
Prenons un exemple, vous êtes sur un site et vous ne trouvez pas ce qui vous intéresse. Ce site a une zone de « recherche », vous allez alors saisir du texte dans cette zone. Il est facile de comprendre que la page de résultat qui va s’afficher sera en fonction de ce que vous avez saisi. Alors on peut se poser la question : « Mais comment la page de résultat est arrivée sur mon ordinateur ? »
Cela va se passer en 2 temps :
- le navigateur va envoyer au serveur, les valeurs que vous avez saisies pour la recherche
- le serveur va récupérer ces valeurs, effectuer la recherche dans ses bases de données et renvoyer la page avec les résultats.
Voici quelques exemples de pages de recherches :
- https://culture-informatique.net/?s=classe+d+adresse+ip&submit=search
- https://culture-informatique.net/?s=serveur+dns+dhcp&submit=search
- http://www.google.fr/?gfe_rd=cr&gws_rd=ssl#q=culture+informatique
- http://www.asus.com/fr/search/results.aspx?SearchKey=wifi&SearchType=Products&Category=Notebooks&IsSupport=True&Page=1
Ce que l’on peut constater dans ces exemples c’est que les URL des pages demandées sont toutes complexes. Elles contiennent des symboles : « ? » et « & »
On pourrait simplifier cela et l’afficher comme ça :
www.site-internet.net/page ? parametre1=valeur1 & parametre2=valeur2
(Attention, j’ai ajouté des espaces pour faciliter la lecture, mais il n’y en a pas)
- En rouge : l’adresse du site et la page demandée
- en bleu : le » ? » permet d’indiquer le début des paramètres
- en orange : les paramètres sont toujours passés sous la forme : Paramètre = valeur-du-paramètre. Exemple : cle=4 ou recherche=test. (dans ce cas les paramètres sont « cle » et « recherche », et les valeurs sont « 4 » et « test »)
- en vert : le » & » sépare les différents paramètres.
Notez, que chaque développeur de site choisit les noms de ses paramètres. Comme par exemple, les paramètres de valeur de recherche ne sont pas les mêmes sur le site culture-informatique : « s », que sur le site asus.com : « SearchKey »)
N’hésitez pas à essayer la recherche sur ce site pour voir comment se comporte l’URL. Vous trouverez la recherche à droite, un peu haut dessus de ce texte.
La méthode POST
La méthode GET est utilisée dans les envois de données simples, mais il peut être nécessaire d’envoyer :
- beaucoup plus de données (beaucoup d’informations)
- des données qui ne sont pas du texte (des images par exemple),
- …
Un exemple
Prenons un exemple, vous voulez faire imprimer une photo. Vous allez sur un site Internet proposant ce service, et vous devez envoyer votre photo au site. Vous comprenez facilement que la photo ne peut pas être envoyée avec la méthode GET et un paramètre du style :
www.sitephoto.com/?photo=11d0e8de4507fd0adf08415dfabb960fd00f0df….
Une photo faisant généralement plusieurs Mo (millions de caractères), ce n’est pas possible de mettre tout ça dans une URL car la longueur maximum des paramètres des URL est limitée à 256 caractères et la globalité de l’URL est limitée à 2048 caractères.
Dans ce cas, il est possible d’utiliser une autre méthode proposée par le protocole http, la méthode POST.
La méthode POST va permettre d’envoyer des données comme si vous envoyez un mail avec un pièce jointe.
La méthode POST va utiliser le codage MIME pour indiquer de quel type de données il s’agit.
Pour rester simple, le format MIME permet de coder n’importe quel type de données sous forme de texte pour permettre de les envoyer. MIME veut dire Multipurpose Internet Mail Extension. C’est un format qui permet l’envoi par mail de pièces jointes de n’importe quel type.
Voici quelques exemples de description de format MIME :
|
Données |
Format Mime |
| Un fichier image | Content-Type: image/jpeg; |
| Un fichier texte | Content-Type: text/plain; |
| Un fichier de données brutes | Content-Type: application/octet-stream; |
Différences entre GET et POST
On pourrait se dire : « mais à mon niveau, je m’en fous qu’un site utilise l’une ou l’autre de ces méthodes ! ». Oui, c’est vrai.
Mais, ces 2 méthodes ne se comportent pas exactement pareil, comme par exemple au niveau du cache. Si vous faites « précédent » sur une page utilisant la méthode GET, cela fonctionne sans problème. Par contre, si vous faites « précédent » sur une page utilisant la méthode POST, vous aurez un message d’erreur du navigateur, tel que:
 avec Google Chrome |
 avec Mozilla Firefox avec Mozilla Firefox |
Pourquoi ces messages d’erreur avec la méthode POST ?
On pourrait se poser la question « mais pourquoi cela fonctionne avec GET, et pourquoi ça ne fonctionne pas avec POST ? ».
Il faut juste comprendre qu’avec POST, les données n’étant pas dans l’URL, il n’est pas possible de se repositionner précisément à un endroit précis. (Avec GET, comme on repasse exactement tous les paramètres dans l’URL, on repasse non seulement la page, mais aussi tout le contexte).
C’est une des différences notoire entre les sites utilisant GET et ceux utilisant POST, mais vous verrez qu’il en existe bien d’autres.
Dans la 3ème partie de cette série d’articles consacrés au protocole HTTP, nous regarderons :
- Les différences entre la méthode GET et la méthode POST.
- Les autres méthodes du protocole HTTP
- Nous aborderons une évolution importante de HTTP
- Je vous donnerai quelques noms de serveurs HTTP répandus.
- Et nous commencerons à parler de HTTPS
Vous trouverez cet article ici : C’est quoi un serveur http ? – Partie 3
Liste des articles consacrés au protocole HTTP / HTTPS
- C’est quoi un serveur http ou serveur web ?
- C’est quoi un serveur http ou serveur web ? – Partie 2
- C’est quoi un serveur http ou serveur web ? – Partie 3
- C’est quoi la différence entre http et https ?
Et enfin, un article qui n’est pas directement lié au http ou https, mais qui concerne la sécurité des sites en https : C’est quoi un certificat numérique ?

